Basic Filtering#
The Filter Object#
The core object in GCM-Filters is the gcm_filters.Filter object. Its full documentation below enumerates all possible options.
- gcm_filters.Filter(filter_scale: float, dx_min: float, filter_shape: ~gcm_filters.filter.FilterShape = FilterShape.GAUSSIAN, transition_width: float = 3.141592653589793, ndim: int = 2, n_steps: int = 0, grid_type: ~gcm_filters.kernels.GridType = GridType.REGULAR, grid_vars: dict = <factory>) None[source]#
A class for applying diffusion-based smoothing filters to gridded data.
- Parameters:
filter_scale (float) – The filter scale, which has different meaning depending on filter shape
dx_min (float) – The smallest grid spacing. Should have same units as
filter_scalen_steps (int, optional) – Number of total steps in the filter
n_steps == 0means the number of steps is chosen automaticallyfilter_shape (FilterShape) –
FilterShape.GAUSSIAN: The target filter has shape \(e^{-(k filter_scale)^2/24}\)FilterShape.TAPER: The target filter has target grid scale Lf. Smaller scales are zeroed out. Scales larger thanpi * filter_scale / 2are left as-is. In between is a smooth transition.
transition_width (float, optional) – Width of the transition region in the “Taper” filter. This is a nondimensional parameter. Theoretical minimum is 1; not recommended.
ndim (int, optional) – Laplacian is applied on a grid of dimension ndim
grid_type (GridType) – what sort of grid we are dealing with
grid_vars (dict) – dictionary of extra parameters used to initialize the grid Laplacian
- gcm_filters.filter_spec#
- Type:
FilterSpec
Details related to filter_scale, filter_shape, transition_width, and n_steps can be found in the Filter Theory.
The following sections explain the options for grid_type and grid_vars in more detail.
Grid types#
To define a filter, we need to pick a grid and associated Laplacian that matches our data. The currently implemented grid types are:
In [1]: import gcm_filters
In [2]: list(gcm_filters.GridType)
Out[2]:
[<GridType.REGULAR: 1>,
<GridType.REGULAR_AREA_WEIGHTED: 2>,
<GridType.REGULAR_WITH_LAND: 3>,
<GridType.REGULAR_WITH_LAND_AREA_WEIGHTED: 4>,
<GridType.IRREGULAR_WITH_LAND: 5>,
<GridType.MOM5U: 6>,
<GridType.MOM5T: 7>,
<GridType.TRIPOLAR_REGULAR_WITH_LAND_AREA_WEIGHTED: 8>,
<GridType.TRIPOLAR_POP_WITH_LAND: 9>,
<GridType.VECTOR_C_GRID: 10>,
<GridType.VECTOR_B_GRID: 11>]
This list will grow as we implement more Laplacians.
The following table provides an overview of these different grid type options: what grid they are suitable for, whether they handle land (i.e., continental boundaries), what boundary condition the Laplacian operators use, and whether they come with a scalar or vector Laplacian. You can also find links to example usages.
|
Grid |
Handles land |
Boundary condition |
Laplacian type |
Example |
|---|---|---|---|---|---|
|
Cartesian grid |
no |
periodic |
Scalar Laplacian |
|
|
Cartesian grid |
yes |
periodic |
Scalar Laplacian |
see below |
|
locally orthogonal grid |
yes |
periodic |
Scalar Laplacian |
Example: Different filter types; Example: Filtering on a tripole grid |
|
Velocity-point on Arakawa B-Grid |
yes |
periodic |
Scalar Laplacian |
|
|
Tracer-point on Arakawa B-Grid |
yes |
periodic |
Scalar Laplacian |
|
|
locally orthogonal grid |
yes |
tripole |
Scalar Laplacian |
|
|
yes |
periodic |
Vector Laplacian |
||
|
no |
periodic |
Vector Laplacian |
Grid types with scalar Laplacians can be used for filtering scalar fields (such as temperature), and grid types with vector Laplacians can be used for filtering vector fields (such as velocity).
Grid types for simple fixed factor filtering#
The remaining grid types are for a special type of filtering: simple fixed factor filtering to achieve a fixed coarsening factor (see also the Filter Theory). If you specify one of the following grid types for your data, gcm_filters will internally transform your original (locally orthogonal) grid to a uniform Cartesian grid with dx = dy = 1, and perform fixed factor filtering on the uniform grid. After this is done, gcm_filters transforms the filtered field back to your original grid.
In practice, this coordinate transformation is achieved by area weighting and deweighting (see Filter Theory). This is why the following grid types have the suffix AREA_WEIGHTED.
|
Grid |
Handles land |
Boundary condition |
Laplacian type |
Example |
|---|---|---|---|---|---|
|
locally orthogonal grid |
no |
periodic |
Scalar Laplacian |
|
|
locally orthogonal grid |
yes |
periodic |
Scalar Laplacian |
Example: Different filter types; Example: Filtering on a tripole grid |
|
locally orthogonal grid |
yes |
tripole |
Scalar Laplacian |
Grid variables#
Each grid type from the above two tables has different grid variables that must be provided as Xarray DataArrays. For example, let’s assume we are on a Cartesian grid (with uniform grid spacing equal to 1), and we want to use the grid type REGULAR_WITH_LAND. To find out what the required grid variables for this grid type are, we can use this utility function.
In [3]: gcm_filters.required_grid_vars(gcm_filters.GridType.REGULAR_WITH_LAND)
Out[3]: ['wet_mask']
wet_mask is a binary array representing the topography on our grid. Here the convention is that the array is 1 in the ocean (“wet points”) and 0 on land (“dry points”).
In [4]: import numpy as np
In [5]: import xarray as xr
In [6]: ny, nx = (128, 256)
In [7]: mask_data = np.ones((ny, nx))
In [8]: mask_data[(ny // 4):(3 * ny // 4), (nx // 4):(3 * nx // 4)] = 0
In [9]: wet_mask = xr.DataArray(mask_data, dims=['y', 'x'])
In [10]: wet_mask.plot()
Out[10]: <matplotlib.collections.QuadMesh at 0x7fa5d210ba10>
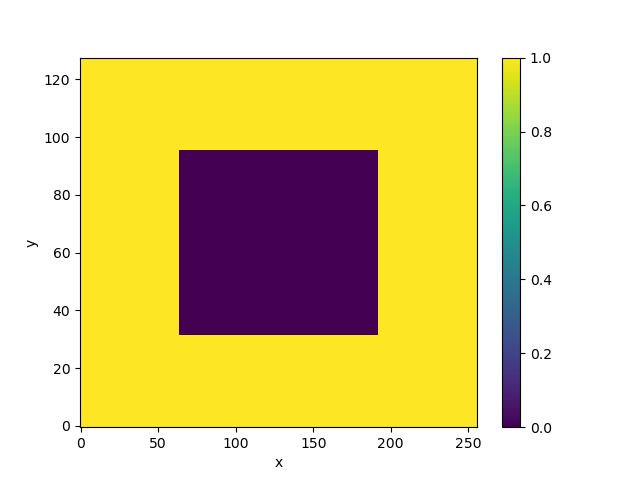
We have made a big island.
Note
Some more complicated grid types require more grid variables.
The units for these variables should be consistent, but no specific system of units is required.
For example, if grid cell edge lengths are defined using kilometers, then the filter scale and dx_min should also be defined using kilometers, and the grid cell areas should be defined in square kilometers.
Creating the Filter Object#
We create a filter object as follows.
In [11]: filter = gcm_filters.Filter(
....: filter_scale=4,
....: dx_min=1,
....: filter_shape=gcm_filters.FilterShape.TAPER,
....: grid_type=gcm_filters.GridType.REGULAR_WITH_LAND,
....: grid_vars={'wet_mask': wet_mask}
....: )
....:
In [12]: filter
Out[12]: Filter(filter_scale=4, dx_min=1, filter_shape=<FilterShape.TAPER: 2>, transition_width=3.141592653589793, ndim=2, n_steps=np.int64(16), grid_type=<GridType.REGULAR_WITH_LAND: 3>)
The string representation for the filter object in the last line includes some of the parameters it was initiliazed with, to help us keep track of what we are doing. We have created a Taper filter that will filter our data by a fixed factor of 4.
Applying the Filter#
We can now apply the filter object that we created above to some data. Let’s create a random 3D cube of data that matches our grid.
In [13]: nt = 10
In [14]: data = np.random.rand(nt, ny, nx)
In [15]: da = xr.DataArray(data, dims=['time', 'y', 'x'])
In [16]: da
Out[16]:
<xarray.DataArray (time: 10, y: 128, x: 256)> Size: 3MB
array([[[5.21776211e-01, 1.85812181e-01, 5.09632994e-01, ...,
1.55204527e-01, 8.26205653e-01, 1.50161291e-01],
[4.17836974e-01, 5.00292164e-01, 5.03483474e-01, ...,
4.26433387e-01, 2.93858106e-01, 3.80624857e-03],
[6.86411707e-01, 7.28778095e-01, 4.18883512e-01, ...,
7.11083130e-01, 7.98909615e-01, 9.48140230e-01],
...,
[5.57208022e-01, 6.39532393e-01, 2.85094995e-01, ...,
4.27687052e-01, 9.34362818e-01, 9.97064160e-01],
[6.78811265e-01, 7.19206668e-01, 5.10780908e-01, ...,
6.71478581e-01, 5.87918090e-01, 4.24158386e-01],
[7.23835390e-01, 6.83954052e-01, 9.59126808e-01, ...,
2.71030852e-01, 7.62045662e-01, 8.14452520e-01]],
[[2.07094438e-01, 1.43945451e-01, 4.80712844e-01, ...,
5.33995702e-01, 8.75782679e-01, 4.08513868e-01],
[4.61051881e-01, 4.26662656e-01, 1.27108301e-01, ...,
5.73071948e-01, 5.41757999e-01, 5.17682070e-02],
[4.40090365e-01, 9.75854134e-01, 3.47973986e-01, ...,
1.43260565e-01, 4.57992031e-02, 6.16831284e-01],
...
[6.67732096e-01, 6.71532994e-01, 2.24221076e-01, ...,
8.90900783e-01, 1.46632848e-01, 4.12294401e-01],
[4.74403594e-01, 8.96800067e-01, 9.49373517e-01, ...,
2.70209244e-01, 9.26948377e-02, 5.51064653e-01],
[7.18615045e-01, 9.09835616e-01, 9.32316100e-01, ...,
3.29473840e-01, 3.05700507e-01, 8.17136987e-01]],
[[9.13873957e-02, 6.31417961e-01, 9.11714399e-01, ...,
2.34883279e-01, 8.37683536e-01, 2.29913673e-02],
[3.98997139e-01, 6.73168022e-01, 4.43353243e-01, ...,
6.53006715e-01, 3.96462038e-01, 1.93883741e-01],
[2.54504849e-02, 6.65139060e-01, 7.04924165e-01, ...,
8.43878075e-01, 8.14807259e-01, 8.13738357e-01],
...,
[8.41581749e-01, 6.02778473e-01, 6.50114368e-01, ...,
6.93321280e-01, 9.71890829e-01, 9.63010238e-01],
[4.19803196e-01, 5.40536619e-02, 5.09533269e-01, ...,
9.96042549e-01, 3.32123612e-01, 9.46426017e-01],
[6.11384050e-01, 1.59283930e-01, 7.08724225e-01, ...,
3.47973851e-01, 2.65820799e-01, 4.10689022e-01]]])
Dimensions without coordinates: time, y, x
We now mask our data with the wet_mask.
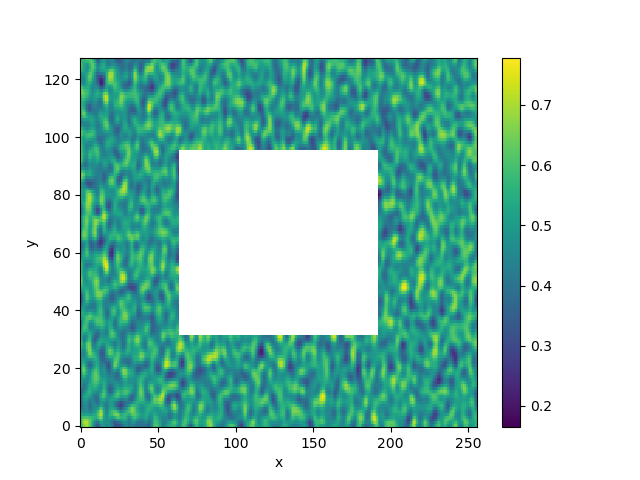
In [17]: da_masked = da.where(wet_mask)
In [18]: da_masked.isel(time=0).plot()
Out[18]: <matplotlib.collections.QuadMesh at 0x7fa5d205d590>

Now that we have some data, we can apply our filter. We need to specify which dimension names to apply the filter over. In this case, it is y, x.
Warning
The dimension order matters! Since some filters deal with anisotropic grids, the latitude / y dimension must appear first in order to obtain the correct result. That is not an issue for this simple (isotropic) toy example but needs to be kept in mind for applications on real GCM grids.
In [19]: %time da_filtered = filter.apply(da_masked, dims=['y', 'x'])
CPU times: user 122 ms, sys: 9.76 ms, total: 131 ms
Wall time: 131 ms
In [20]: da_filtered
Out[20]:
<xarray.DataArray (time: 10, y: 128, x: 256)> Size: 3MB
array([[[0.53162234, 0.55012804, 0.57591331, ..., 0.51191791,
0.5122927 , 0.51896054],
[0.52086228, 0.54551018, 0.57224834, ..., 0.4950176 ,
0.49435163, 0.5025127 ],
[0.54399292, 0.56816295, 0.57979308, ..., 0.4900585 ,
0.49981663, 0.51788595],
...,
[0.58711092, 0.56901489, 0.55345188, ..., 0.58317023,
0.60633918, 0.60322089],
[0.61327841, 0.59318569, 0.57489801, ..., 0.59702558,
0.62175278, 0.62597156],
[0.58125458, 0.5806832 , 0.58435602, ..., 0.55870683,
0.5716119 , 0.57939742]],
[[0.43944325, 0.41250052, 0.40829806, ..., 0.60151165,
0.52981129, 0.47672825],
[0.41140301, 0.41299064, 0.42889672, ..., 0.56695525,
0.47554639, 0.42595864],
[0.40844046, 0.44111987, 0.47307682, ..., 0.51660867,
0.42343683, 0.3916682 ],
...
[0.49954385, 0.55026924, 0.54412574, ..., 0.41744769,
0.38582123, 0.42170171],
[0.57895448, 0.63944398, 0.62829438, ..., 0.45839241,
0.43128652, 0.48235095],
[0.58691395, 0.6411162 , 0.62410954, ..., 0.48317819,
0.45106283, 0.49634956]],
[[0.40785744, 0.4412378 , 0.49642323, ..., 0.40447391,
0.41421262, 0.40750587],
[0.43548814, 0.47638131, 0.53598218, ..., 0.43429282,
0.4353626 , 0.42901458],
[0.50412404, 0.53348004, 0.57844336, ..., 0.504851 ,
0.50479046, 0.5007994 ],
...,
[0.67511831, 0.62351507, 0.57374421, ..., 0.5089636 ,
0.61887659, 0.68203244],
[0.57765127, 0.5449893 , 0.52655367, ..., 0.49311462,
0.56744012, 0.59550291],
[0.46204323, 0.46511007, 0.48996404, ..., 0.4368689 ,
0.4717036 , 0.47403466]]])
Dimensions without coordinates: time, y, x
Let’s visualize what the filter did.
In [21]: da_filtered.isel(time=0).plot()
Out[21]: <matplotlib.collections.QuadMesh at 0x7fa5d1f07c50>
Using Dask#
Up to now, we have filtered eagerly; when we called .apply, the results were computed immediately and stored in memory.
GCM-Filters is also designed to work seamlessly with Dask array inputs. With dask, we can filter lazily, deferring the filter computations and possibly executing them in parallel.
We can do this with our synthetic data by converting them to dask.
In [22]: da_dask = da_masked.chunk({'time': 2})
In [23]: da_dask
Out[23]:
<xarray.DataArray (time: 10, y: 128, x: 256)> Size: 3MB
dask.array<xarray-<this-array>, shape=(10, 128, 256), dtype=float64, chunksize=(2, 128, 256), chunktype=numpy.ndarray>
Dimensions without coordinates: time, y, x
We now filter our data lazily.
In [24]: da_filtered_lazy = filter.apply(da_dask, dims=['y', 'x'])
In [25]: da_filtered_lazy
Out[25]:
<xarray.DataArray (time: 10, y: 128, x: 256)> Size: 3MB
dask.array<transpose, shape=(10, 128, 256), dtype=float64, chunksize=(2, 128, 256), chunktype=numpy.ndarray>
Dimensions without coordinates: time, y, x
Nothing has actually been computed yet. We can trigger computation as follows:
In [26]: %time da_filtered_computed = da_filtered_lazy.compute()
CPU times: user 373 ms, sys: 33.3 ms, total: 406 ms
Wall time: 307 ms
Here we got only a very modest speedup because our example data are too small. For bigger data, the performance benefit will be more evident.